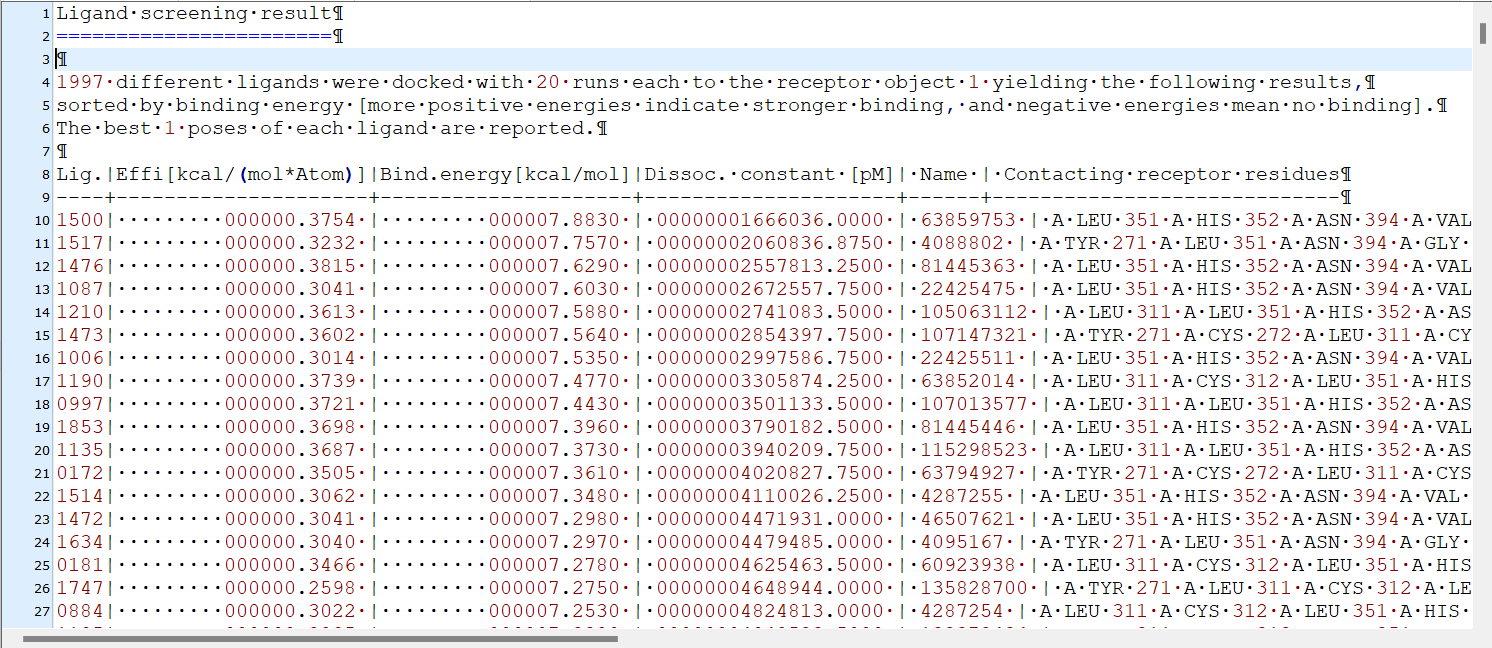
El software YASARA Structure genera resultados en fichero *.tab después de realizar una simulación de "molecular docking" como los que vemos justo debajo. Para cada libreria de moléculas que estás testando genera un fichero de este tipo. Si tu libreria es de 850,000 compuestos, lo lógico es que la tengas dividida en tantos ficheros *.sdf como sean necesarios para incluir en cada uno de ellos un máximo de 4,000 moléculas (yo he testado este número y YASARA termina el cálculo de las 4,000).
¿Cómo gestionas la información contenida en los al menos 211 ficheros *.tab que se te van a generar cuando termine el cálculo con toda la libreria?
El siguiente script para Python 3, ejecutado en Linux te resuelve el problema, tendrás que adecuar en él la ruta donde se encuentran tus archivos *.lig (en este ejemplo: "/home/jant.encinar/py-linux/01-combina-logs/logs_DOCKING/") y el hombre del fichero de texto que almacenará los resultados de salida del script, como datos en columnas separadas por tabuladores (en este ejemplo: "_todosLOGs-linux.txt"). Este fichero es fácilmente exportable a Excel.
import os
import glob
# Definir la ruta de la carpeta donde se encuentran los archivos de registro
log_folder = "/home/jant.encinar/py-linux/01-combina-logs/logs_DOCKING/"
# Definir el nombre del archivo donde se guardarán todos los registros
output_file = log_folder + "_todosLOGs-linux.txt"
# Iterar sobre los archivos de registro en la carpeta
with open(output_file, "w") as outfile:
for filepath in glob.glob(log_folder + "*.log"):
log_file = str(filepath)
with open(log_file, "r") as infile:
# Leer todo el contenido del archivo
content = infile.read()
# Buscar la cadena de inicio y fin de los datos a extraer
start_str = "----+---------------------+---------------------+---------------------+------+-----------------------------"
end_str = "The random seed used during docking was 0."
start_index = content.find(start_str)
end_index = content.find(end_str)
# Si se encontró la cadena de inicio y fin, extraer los datos entre ellas
if start_index != -1 and end_index != -1:
data = content[start_index + len(start_str):end_index].strip()
# Reemplazar los caracteres de separación de columna "|" por "\t"
data = data.replace("|", "\t")
# Escribir los datos en el archivo de salida, incluyendo el nombre del archivo de origen
for line in data.split("\n"):
outfile.write(f"{os.path.basename(log_file)}\t{line}\n")